Tecnologías y Herramientas para Análisis de Big Data
TECNOLOGÍAS DE BIG DATA
El ecosistema Apache Hadoop
Durante muchos años, Apache Hadoop ha sido el proyecto tecnológico más popular para realizar análisis de big data. Hadoop es un entorno software que permite implementar procesos de análisis de datos basados en una estrategia denominada MapReduce.
En esta estrategia, se puede descomponer un problema complejo (análisis de un conjunto completo de datos masivos) en muchos problemas más pequeños y tratables (operaciones sobre partes de esos datos, fase Map) para después recoger y unificar los resultados (fase Reduce).
Sin embargo, Hadoop no es solo un proyecto para análisis de big data, sino también un ecosistema de proyectos y productos relacionados entre sí. Todos ellos están conectados con el análisis de big data, pero cada componente individual ofrece una funcionalidad específica (resuelve un problema o función en concreto, dentro del esquema general).
La figura muestra el esquema original del ecosistema Hadoop, con algunos de sus componentes más relevantes.
- En la base tenemos el Hadoop Distributed FileSystem (HDFS), un sistema de ficheros distribuido, que permite almacenar cantidades masivas de datos repartidos entre un gran número de nodos de un sistema de computación distribuido.
- Sobre esta capa inferior, se suelen utilizar bases de datos específicamente diseñadas para trabajar con big data, tales como HBase o Cassandra. Estos componentes facilitan la gestión y acceso a la colección masiva de datos que se desea analizar. Algunos de ellos se verán en la siguiente sección sobre bases de datos no convencionales para big data.
El tercer nivel, el corazón de la arquitectura, está ocupado por el propio proyecto Hadoop, la tecnología que permite procesar y analizar conjuntos de datos masivos y complejos siguiendo el paradigma MapReduce. En la actualidad, Hadoop está siendo sustituido por otras tecnologías de procesamiento de big data más sofisticadas y potentes como Spark.
Finalmente, sobre Hadoop aparecen diversas capas de proyectos que ofrecen a los usuarios del sistema distintas interfaces para trabajar con big data más cómodamente.
A la izquierda se ve Hive, un sistema que permite enviar consultas en lenguaje similar a SQL, para tratar con big data con una interfaz parecida a una base de datos relacional convencional. En el centro se ve a Pig, para crear procesos de análisis de datos secuenciales de forma amigable e intuitiva. A la derecha Mahout, proyecto enfocado a aplicar modelos de minería de datos y machine learning sobre big data.
En la actualidad, Spark está desbancando progresivamente a Hadoop como motor principal del ecosistema, remodelando muchos de los componentes del mismo, sobre todo en la capa más alta que interactúa con el usuario final.
Así, aparecen nuevos componentes más potentes para trabajar con big data mediante SQL (Spark SQL); trabajo con flujos de datos, que no existía en Hadoop (Spark Streaming), así como componentes más sofisticados para, por ejemplo, minería de datos y machine learning (MLlib) o análisis de grafos y redes (GraphX).
La evolución que ha sufrido el ecosistema Hadoop desde su etapa inicial hasta la actualidad ha sido muy radical, especialmente por la sustitución del propio motor principal de la plataforma (Hadoop) por un nuevo motor más versátil y potente (Spark), que ofrece la promesa de cerrar la brecha entre los entornos de laboratorio de análisis y análisis en producción.
Introducción a Bases de Datos NoSQL
Tradicionalmente, un sistema de base de datos se organizaba internamente según lo que conocemos como modelo relacional. En este modelo, los datos se organizan en tablas cuyas columnas corresponden a diversas variables, cada una con un tipo predefinido de antemano: número entero, decimal, cadena de caracteres, valor lógico (verdadero/falso), etc. En este modelo relacional se puede construir un esquema descriptivo que indica, para cada tabla, que campos (columnas) contiene y de qué tipo son los valores que se guardan en cada columna.
Este esquema de organización es válido para datos estructurados, en los que se conoce de antemano qué campos y de qué tipo son los valores que contienen. Sin embargo, como ya se ha explicado anteriormente (sección 4.1.3), el big data se caracteriza porque también contiene datos semi-estructurados, así como datos no estructurados. Las bases de datos tradicionales, basadas en el modelo relacional, no ofrecen la flexibilidad necesaria para poder almacenar datos de estos dos tipos, puesto que su esquema de organización rígido no proporciona la flexibilidad necesaria.
Como alternativa para resolver este problema, surgen las llamadas bases de datos no convencionales, o también conocidas como NoSQL (Not only SQL). SQL es el lenguaje más habitual para realizar consultas a una base de datos relacional. Así que el nombre NoSQL aclara que estas nuevas bases de datos, además de ofrecer muchas de ellas una opción relacional convencional, permiten organizar los datos siguiendo estrategias alternativas mucho más flexibles, adaptables tanto a datos semi-estructurados(ficheros XML, JSON, etc.) como a datos no estructurados, o con estructuras no contempladas por los sistemas de bases de datos tradicionales (por ejemplo, datos de redes y grafos).
Existen 4 grandes familias de bases de datos no convencionales:
- Bases de datos de esquema clave-valor: es la versión más sencilla. Almacenan simplemente parejas datos clave-valor, en los cuales la clave nunca se puede repetir. Para recuperar un valor, simplemente se busca la clave correspondiente al mismo.
- Bases de datos distribuidas por columnas: particionan los datos por columnas, de manera que se pueden paralelizar consultas sobre subconjuntos de datos muy grandes, ya que están almacenados en diferentes nodos de un sistema distribuido. Dos ejemplos de este tipo, ya explicados al hablar del ecosistema Hadoop, son HBase y Cassandra.
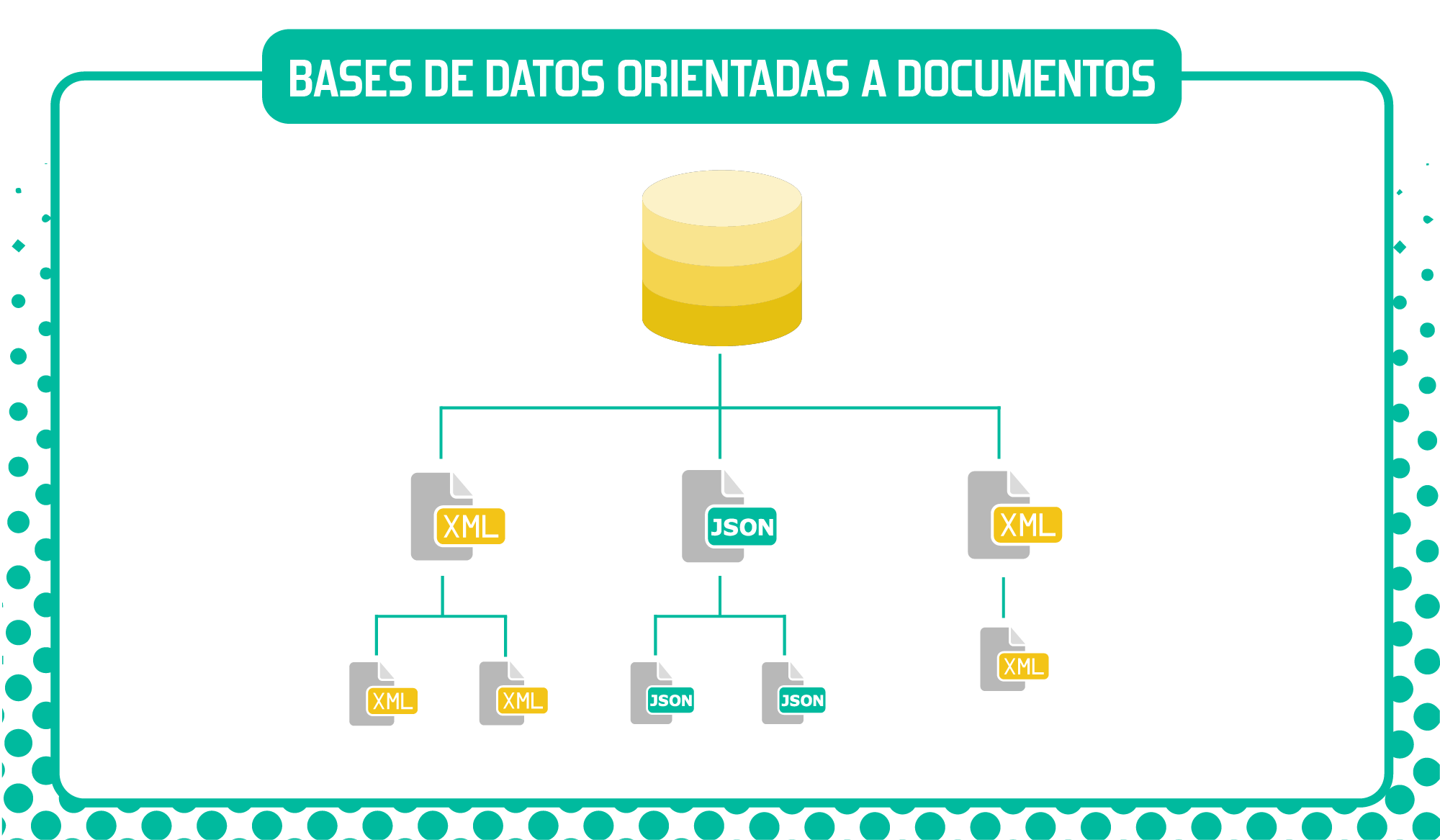
- Bases de datos orientadas a documentos: en este caso también almacenan pares por clave, pero cada clave está asociada a un documento representado mediante un formato para datos semi-estructurados (XML, JSON, YAML, etc.). Los documentos, a su vez, pueden contener muchos otros pares clave-valor, clave-array (para listas de datos) u otros documentos, formando una estructura anidada.
- Bases de datos para grafos: almacenan explícitamente información sobre nodos y sus relaciones, optimizando las consultas que recorren partes del grafo o el grafo en su totalidad. Dos ejemplo populares de este tipo son Neo4J y Titan, la última orientada a manejo de grafos de gran tamaño (120 * 109 nodos). A cambio de esta gran potencia, normalmente este tipo de bases de datos exigen aprender su propio lenguaje específico para realización de consultas, que suele ser bastante diferente de los lenguajes de programación a los que se suele estar acostumbrado.
Francisco Javier Cervigon Ruckauer